superagent+cheerio+(eventproxy || async)实现简单的爬虫
作为node初学者,对node的一切充满了好奇,这里记录一下运用node的一些库完成的小爬虫。
这里不得不对TJ表达出崇高的敬意,superagent,cheerio这些库都是由他贡献的,node第一框架express也是TJ大神贡献的。
搭建node.js开发环境
安装HomeBrew
$ ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/install)"
安装node.js
$ brew install node
安装完成后,查看版本号
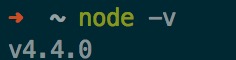
$ node -v
这个时候可以看到安装的node.js的版本号
包管理器 npm
npm 可以自动管理包的依赖. 只需要安装你想要的包, 不必考虑这个包的依赖包.
在 PHP 中, 包管理使用的 Composer, python 中,包管理使用 easy_install 或者 pip,ruby 中我们使用 gem。而在 Node.js 中,对应就是 npm,npm 是 Node.js Package Manager 的意思。
一个简单express应用
新建一个app文件夹,然后进入里面安装express
$ mkdir app && cd app
# 使用淘宝的npm镜像
$ npm install express--registry=https://registry.npm.taobao.org
安装完成后,可以看见app文件夹下面多出一个node_modules文件夹,里面有express的依赖包
$ cd node_modules
$ npm list
我们来编写一个最简单的express应用
新建一个app.js
$ touch app.js
$ sudo vim app.js
输入下面代码
// 引入 `express` 模块
var express = require('express');
// 调用 express 实例,它是一个函数,不带参数调用时,会返回一个 express 实例,将这个变量赋予 app 变量。
var app = express();
// app 本身有很多方法,其中包括最常用的 get、post、put/patch、delete,在这里我们调用其中的 get 方法,为我们的 `/` 路径指定一个 handler 函数。
// 这个 handler 函数会接收 req 和 res 两个对象,他们分别是请求的 request 和 response。
// request 中包含了浏览器传来的各种信息,比如 query 啊,body 啊,headers 啊之类的,都可以通过 req 对象访问到。
// res 对象,我们一般不从里面取信息,而是通过它来定制我们向浏览器输出的信息,比如 header 信息,比如想要向浏览器输出的内容。这里我们调用了它的 #send 方法,向浏览器输出一个字符串。
app.get('/', function (req, res, next) {
res.send('Hello World');
});
// 定义好我们 app 的行为之后,让它监听本地的 3000 端口。这里的第二个函数是个回调函数,会在 listen 动作成功后执行,我们这里执行了一个命令行输出操作,告诉我们监听动作已完成。
app.listen(3000, function () {
console.log('app is listening at port 3000');
});
执行
node app.js
终端中会输出 app is listening at port 3000。这时我们打开浏览器,访问http://localhost:3000/,会出现 Hello World。
superagent+cheerio实现爬虫
安装下依赖包
$ cd node_modules
$ npm install superagent,cheerio,async --save
直接看代码
//node.js的jquery库,网页分析库
var cheerio = require('cheerio');
//superagent相当于一个轻量级的ajax api
var superagent = require('superagent');
//node.js自带url处理库,详见nodejs文档
var url = require('url');
//async提供简单,强大的功能来处理异步JavaScript
var async = require('async');
//nodejs自带文件和文件夹处理库
//此处应用图片下载和文件夹创建
var fs = require('fs');
var baseUrl = 'http://www.2mm.la/',
baseDir = './images';
//创建文件夹存储图片
fs.exists(baseDir, function(exists){
if(!exists){
fs.mkdir(baseDir, 0777, function(err){
if(!err){
console.log('create dir ok');
}
});
}
});
var picUrlList = []; //存储图片地址,并发下载
var mmLaList = []; //存储信息
//superagent抓取http://www.2mm.la/的内容
superagent.get(baseUrl)
.end(function(err, src){
//错误处理
if(err){
return console.error(err);
}
//src里面有很多信息,大家可以打印出来看看,这边我们需要html网页内容(src.text)
//把src.text传给cheerio.load(),实现一个jquery变量,命名为$
//之后做的工作就是jquery解析网页!
var $ = cheerio.load(src.text);
$('.hm').each(function(index,element){
$element = $(element);
var titleArr = $element.find('#ka').attr('alt').split(' ');
var picHref = url.resolve('http://',$element.find('#ka').attr('name'))
picUrlList.push({
href: picHref,
name: $element.find('#ka').attr('name').split('\/')[3]
});
mmLaList.push({
title: titleArr.shift(),
picSrc: picHref,
videoSrc: url.resolve(baseUrl, $element.find('#ha').attr('href')),
broadCastNum: parseInt($element.find('#si').eq(0).children('span').text()),
category: titleArr.join(' ')
});
console.log(mmLaList);
fs.writeFileSync('./json.txt', JSON.stringify(mmLaList));
});
// 下载图片
//async.mapLimit对集合中的每一个元素,执行某个异步操作,得到结果。所有的结果将汇总到最终的callback里
//第二个参数5标识最多并发5个,最终传给callback
async.mapLimit(picUrlList, 5, function(item, callback){
var stream = fs.createWriteStream('./images/'+ item.name +'.jpg');
req = request.get(item.href).pipe(stream);
callback(null, req);
}, function(err, res){
if(!err){
console.log('图片下载完毕');
}
});
});
附上库地址1111
-
superagent(http://visionmedia.github.io/superagent/)
-
cheerio(https://github.com/cheeriojs/cheerio)
Written on June 29, 2016